I’m going over Chapter 5 in Casella and Berger’s (CB) “Statistical Inference”, specifically Section 5.5: Convergence Concepts, and wanted to document the topic of convergence in probability with some plots demonstrating the concept.
From CB, we have the definition of convergence in probability: a sequence of random variables converges in probability to a random variable , if for every ,
Intuitively, this means that, if we have some random variable and another random variable , the absolute difference between and gets smaller and smaller as increases. The probability that this difference exceeds some value, , shrinks to zero as tends towards infinity. Using convergence in probability, we can derive the Weak Law of Large Numbers (WLLN):
which we can take to mean that the sample mean converges in probability to the population mean as the sample size goes to infinity. If we have finite variance (that is ), we can prove this using Chebyshev’s Law
where as . Intuitively, this means, that the sample mean converges to the population mean – and the probability that their difference is larger than some value is bounded by the variance of the estimator. Because we showed that the variance of the estimator (right hand side) shrinks to zero, we can show that the difference between the sample mean and population mean converges to zero.
We can also show a similar WLLN result for the sample variance using Chebyshev’s Inequality, as:
using the unbiased estimator, , of as follows:
so all we need to do is show that as .
Let’s have a look at some (simple) real-world examples. We’ll start by sampling from a distribution, and compute the sample mean and variance using their unbiased estimators.
# Import numpy and scipy libraries
import numpy as np
from scipy.stats import norm
%matplotlib inline
import matplotlib.pyplot as plt
plt.rc('text', usetex=True)
# Generate set of samples sizes
samples = np.concatenate([np.arange(0, 105, 5),
10*np.arange(10, 110, 10),
100*np.arange(10, 210, 10)])
# number of repeated samplings for each sample size
iterations = 500
# store sample mean and variance
means = np.zeros((iterations, len(samples)))
vsrs = np.zeros((iterations, len(samples)))
for i in np.arange(iterations):
for j, s in enumerate(samples):
# generate samples from N(0,1) distribution
N = norm.rvs(loc=0, scale=1, size=s)
mu = np.mean(N)
# unbiased estimate of variance
vr = ((N - mu)**2).sum()/(s-1)
means[i, j] = mu
vsrs[i, j] = vr
Let’s have a look at the sample means and variances as a function of the sample size. Empirically, we see that both the sample mean and variance estimates converge to their population parameters, 0 and 1.
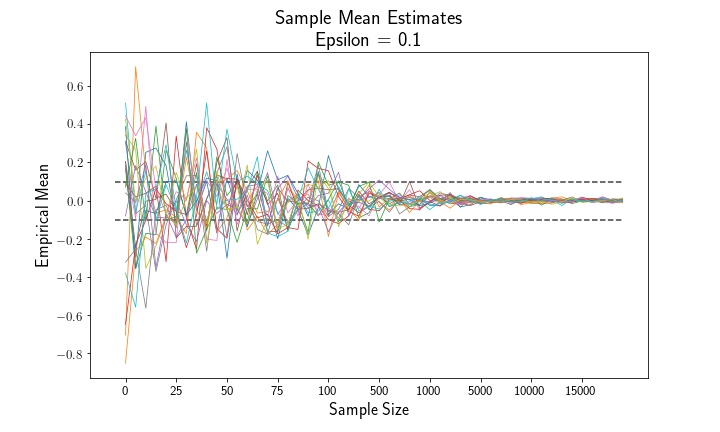
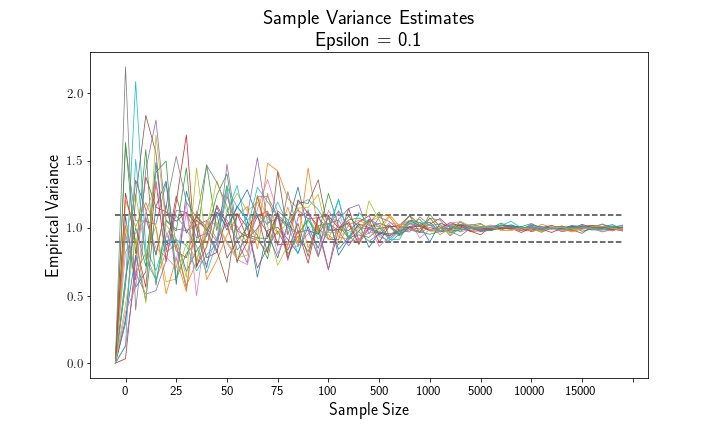
Below is a simple method to compute the empirical probability that an estimate exceeds the epsilon threshold.
def ecdf(data, pparam, epsilon):
"""
Compute empirical probability P( |estimate - pop-param| < epsilon).
Parameters:
- - - - -
data: array, float
array of samples
pparam: float
true population parameter
epsilon: float
threshold value
"""
compare = (np.abs(data - pparam) < epsilon)
prob = compare.mean(0)
return prob
# test multiple epsilon thresholds
e = [0.9, 0.75, 0.5, 0.25, 0.1, 0.05, 0.01]
mean_probs = []
vrs_probs = []
# compute empirical probabilities at each threshold
for E in e:
mean_probs.append(1 - ecdf(means, pparam=0, epsilon=E))
vrs_probs.append(1-ecdf(vsrs, pparam=1, epsilon=E))
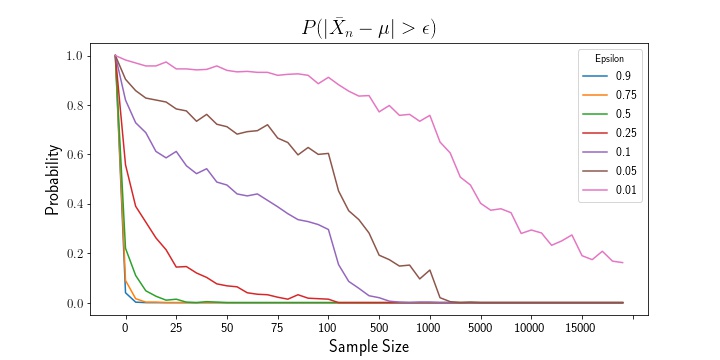
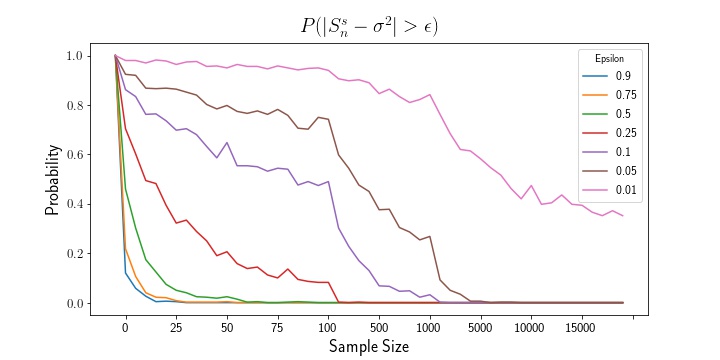
The above plots show that, as sample size increases, the mean estimator and variance estimator both converge to their true population parameters. Likewise, examining the empirical probability plots, we can see that the probability that either estimate exceeds the epsilon thresholds shrinks to zero as the sample size increases.
If we wish to consider a stronger degree of convergence, we can consider convergence almost surely, which says the following:
which considers the entire joint distribution of estimates , rather than all pairwise estimates – the entire set of estimates must converge to as the sample size approaches infinity.